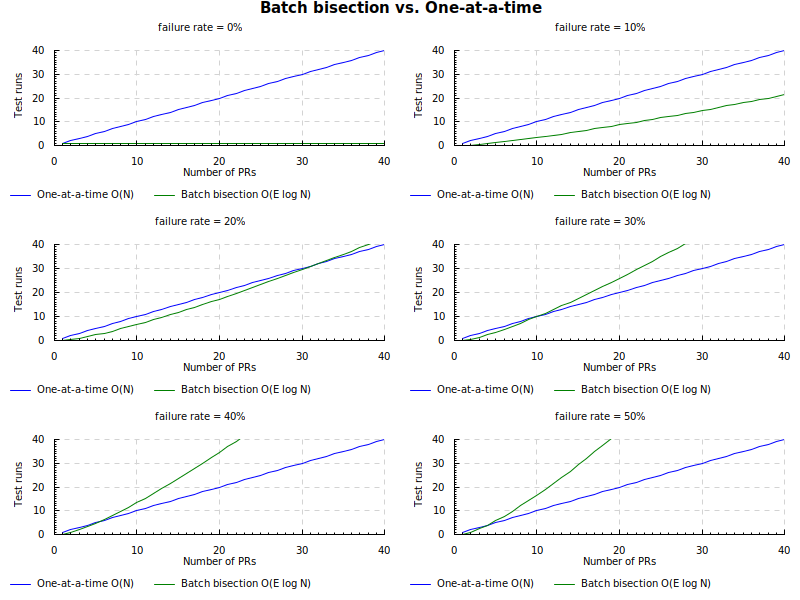
My colleague did some analysis of batching and found through simulation that if the average failure rate of PRs is above a certain level, then the batch bisection strategy takes longer than simply testing one at a time.
Here are some plots of this using the worst-case bounds documented in the bors-ng README.md.
The original bors used a more simple system (it just tested one PR at a time all the time).
The one-at-a-time strategy is O(N), where N is the total number of pull requests.
The batching strategy is O(E log N), where N is again the total number of pull requests and E is the number of > pull requests that fail.
In the plot, you can see for example that if the PR failure rate is 30% and there is a batch of 10 PRs (i.e. 3/10 fail) then batch-bisection is no better than one-at-a-time (worst case). If there are more than 10 PRs in the batch then it's worse.
I would like to use bors-ng but in our situation the batch size and failure rate may both be high. Would it be very difficult to switch to the one-at-a-time strategy if this becomes a problem?
@rvl Super nice analysis! But of course one has to remember that developers submitting PRs have some sanity. And are not randomly sending in crap.
So E should stay low.
We see interesting effects when the build is fragile (we run lots of integration tests), meaning E isn’t tied to specific PRs, but rather to the health of the build. In this case batches are good, since when we’re successful there’s a chance that > 1 PR gets merged.
To tackle build fragilities an interesting command would be keep retrying, as a crutch while we are fixing the build.
one has to remember that developers submitting PRs have some sanity. And are not randomly sending in crap.
you could set up CI to run on the PR beforehand, and not r+ (and/or block with statuses) a PR if the build is otherwise broken. That would help avoid problems with high error rates, unless you really do have a lot of merge conflicts.
Thanks for your responses. It does seem like assuming low E is quite reasonable, if some CI is run beforehand. We do often have problems with merge conflicts, however I haven’t measured it exactly. If there are large batches and a lot of merge conflicts or other errors then we may have to try implementing an option to disable batching.
Wouldn’t it make sense for bors to do that in the first place? Aka if it’s expecting specific statuses on the staging branch, wait for those to be triggered on the PR?
Just wanted to point out that a workaround for large batches is to set different/random priorities for the pull requests when merging. Merges are grouped by priorities.